
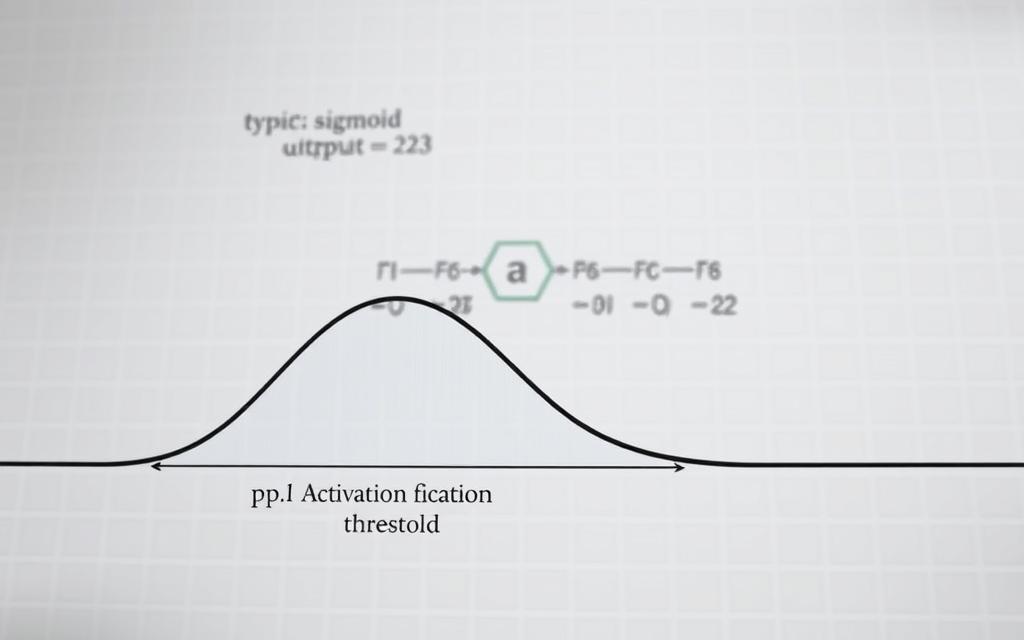
At the heart of every neural network lies a critical component: the activation function. These mathematical gatekeepers decide whether a neuron should be activated, transforming weighted inputs into non-linear outputs. Without them, neural networks would behave like simple linear models, unable to capture complex patterns.
Activation functions introduce non-linearity, enabling neural networks to model intricate relationships in data. This capability is essential for tasks like image classification and natural language processing. By choosing the right activation function, developers can significantly impact a model’s accuracy and performance.
Understanding these functions is key to mastering machine learning. They bridge the gap between raw data and actionable insights, making them indispensable in modern AI applications.
Introduction to Activation Functions in Neural Networks
Activation functions play a pivotal role in shaping neural network behavior. These mathematical tools determine how information flows through the system, enabling complex data processing. Without them, networks would struggle to model intricate patterns.
Neural networks consist of three primary layers: input, hidden, and output. Each layer contains nodes, which process data using weights, biases, and activation functions. This structure allows the network to learn from data effectively.
The feedforward process moves data from input to output layers. During this phase, activation functions introduce non-linearity, making the network capable of handling complex tasks. Backpropagation, on the other hand, adjusts weights and biases to minimize errors.
Node structure is critical for network performance. Each node combines inputs with weights and biases, then applies an activation function to produce an output. This process mimics biological neuron firing, though artificial systems are optimized for computational efficiency.
One challenge in deep learning is the occurrence of “dead neurons.” These nodes stop contributing to learning due to improper gradient flow. Addressing this issue requires careful selection of activation functions.
“Activation functions are the backbone of neural networks, enabling them to learn and adapt.”
Below is a comparison of key processes in neural networks:
| Process | Description |
|---|---|
| Feedforward | Data moves from input to output layers. |
| Backpropagation | Adjusts weights and biases to reduce errors. |
| Node Structure | Combines inputs, weights, biases, and activation functions. |
Understanding these components is essential for building effective models. Activation functions bridge the gap between raw data and actionable insights, making them indispensable in modern AI applications.
What is Activation in a Neural Network?
Activation functions are the driving force behind neural network computations. They determine how neurons process and transmit information, enabling the system to learn complex patterns. These functions transform weighted inputs into outputs, making non-linear relationships possible.

Role of Activation Functions
Activation functions play a critical role in shaping network behavior. They introduce non-linearity, allowing the system to model intricate data relationships. Without them, the network would remain linear and limited in its capabilities.
Each neuron receives inputs, applies weights, and passes the result through an activation function. This process ensures that the network can learn and adapt effectively. The choice of function impacts both accuracy and performance.
Mathematical Representation of Activation Functions
Activation functions are mathematically represented to define their behavior. For example, the ReLU function is expressed as σ(x) = max(0,x), while the sigmoid function is 1/(1+e⁻ˣ). These formulas describe how inputs are transformed into outputs.
The universal formula for activation functions is σ(w·x + b), where w represents weights, x is the input, and b is the bias. This equation forms the foundation of neural network computations.
Derivatives of these functions are essential for backpropagation. They help adjust weights and biases to minimize errors during training. Understanding these mathematical foundations is key to implementing effective models.
Numerical stability and computational complexity are also important considerations. Some functions, like ReLU, are computationally efficient, while others, like sigmoid, may suffer from vanishing gradients. Choosing the right function depends on the specific application and requirements.
Why Non-Linearity is Crucial in Neural Networks
Non-linearity transforms simple models into powerful tools for complex tasks. Without it, even the deepest systems would collapse into single-layer effectiveness. This principle is evident in tasks like apple/banana classification, where linear models fail to capture intricate patterns.
Limitations of Linear Models
Linear regression, while useful for basic tasks, struggles with complex data. Stacked linear layers remain linear, unable to model non-linear relationships. This limitation makes them ineffective for tasks like image recognition or natural language processing.
For example, a deep network with only linear layers behaves like a single-layer system. This reduces its ability to learn and adapt, making it unsuitable for modern AI applications. Non-linearity is essential to unlock the full potential of these systems.
Examples of Non-Linear Activation Functions
Functions like ReLU and sigmoid introduce non-linearity, enabling systems to model complex data. ReLU, defined as σ(x) = max(0,x), is computationally efficient and widely used. Sigmoid, on the other hand, maps inputs to a range between 0 and 1, making it useful for binary classification.
These functions address the vanishing gradient problem, ensuring stable training. By choosing the right function, developers can improve accuracy and performance. Non-linearity also reduces the depth required for effective models, making them more parameter-efficient.
Google’s implementation of sigmoid in exercise models highlights its practical applications. The universal approximation theorem further underscores the importance of non-linearity, proving that even simple systems can approximate complex functions when non-linear elements are introduced.
Types of Activation Functions in Neural Networks
Activation functions are essential tools that shape how systems process and learn from data. They determine the output values of neurons, enabling models to capture complex patterns. Choosing the right function can significantly impact performance and accuracy.

Sigmoid Activation Function
The sigmoid function maps inputs to a range between 0 and 1, making it ideal for binary classification tasks. Its smooth curve ensures gradual transitions, but it can suffer from vanishing gradients in deep networks.
Commonly used in output layers, the sigmoid function is a staple in early models. However, its computational inefficiency has led to the adoption of alternatives like ReLU.
Tanh Activation Function
The hyperbolic tangent (tanh) function scales inputs to a range of -1 to 1. Its zero-centered nature makes it suitable for LSTM networks, where balanced outputs are crucial.
Compared to sigmoid, tanh provides better gradient flow, reducing the risk of vanishing gradients. This advantage has made it a popular choice in recurrent architectures.
ReLU Activation Function
The ReLU function, defined as σ(x) = max(0,x), is computationally efficient and widely used in modern systems. Its simplicity and effectiveness have driven its adoption in tasks like image recognition.
Benchmarks on datasets like ImageNet highlight ReLU‘s superior performance. However, it can lead to “dead neurons” if inputs are consistently negative.
Softmax Activation Function
The softmax function is ideal for multi-class classification, as it converts inputs into probability distributions. Each output value represents the likelihood of a specific class.
This function is commonly used in output layers for tasks like image categorization. Its ability to handle multiple classes makes it indispensable in modern applications.
| Function | Range | Derivatives | Use Cases |
|---|---|---|---|
| Sigmoid | 0 to 1 | σ(x)(1-σ(x)) | Binary classification |
| Tanh | -1 to 1 | 1-σ(x)² | LSTM networks |
| ReLU | 0 to ∞ | 0 or 1 | Image recognition |
| Softmax | 0 to 1 | σ(x)(1-σ(x)) | Multi-class classification |
From early perceptrons to today’s advanced models, activation functions have evolved to meet the demands of complex tasks. Their adoption across industries underscores their importance in driving innovation.
How Activation Functions Impact Model Performance
The efficiency of training models heavily relies on the choice of activation functions. These functions influence how quickly a model learns and how effectively it handles complex data. Understanding their impact is crucial for optimizing performance.

Convergence Speed and Gradient Flow
Activation functions directly affect convergence speed, determining how fast a model reaches optimal accuracy. Functions like ReLU enable faster learning by maintaining consistent gradient flow. This ensures that weights are updated efficiently during training.
Batch normalization can further enhance this process by stabilizing input distributions. This synergy reduces the number of iterations needed for convergence, saving both time and computational resources.
Vanishing and Exploding Gradient Problems
One common challenge in deep learning is the gradient problem, which includes vanishing and exploding gradients. Functions like sigmoid and tanh are prone to vanishing gradient issues, where gradients become too small to update weights effectively.
ReLU avoids this issue by allowing gradients to flow freely for positive inputs. However, it can lead to “dead neurons” if inputs are consistently negative. ELU addresses this by introducing a small negative slope, ensuring all neurons remain active.
“Choosing the right activation function is a balancing act between speed and stability.”
To mitigate exploding gradients, techniques like gradient clipping are often employed. These methods cap gradient values, preventing them from growing too large and destabilizing the model.
Understanding these dynamics helps developers select the best functions for their specific needs. Whether prioritizing speed or stability, the right choice can significantly enhance model performance.
Choosing the Right Activation Function for Your Neural Network
Selecting the optimal activation function can make or break your model’s performance. These functions shape how data flows through hidden layers and output layers, directly impacting accuracy and efficiency. By understanding their roles, you can tailor your architecture to specific tasks like classification or regression.

Activation Functions for Hidden Layers
Hidden layers typically rely on ReLU variants due to their simplicity and efficiency. ReLU is ideal for deep systems, especially when handling image or text data. It avoids the vanishing gradient problem, ensuring stable training.
For deeper architectures, Leaky ReLU is a strong alternative. It prevents “dead neurons” by allowing a small gradient for negative inputs. Tanh is another option, particularly useful when data is centered around zero. Its zero-centered nature aids optimization in certain scenarios.
Activation Functions for Output Layers
Output layers require functions tailored to the task at hand. For binary classification, the sigmoid function is a natural choice. It maps outputs to a range between 0 and 1, making them interpretable as probabilities.
In multi-class tasks, softmax is the go-to function. It converts outputs into probability distributions, enabling clear class distinctions. For regression problems, a linear function is often used, as it allows outputs to take any value.
“The right activation function ensures your model learns effectively and delivers accurate results.”
Here’s a quick guide to help you choose:
- ReLU: Default for hidden layers due to its efficiency.
- Leaky ReLU: Use in deeper networks to avoid dead neurons.
- Tanh: Ideal for zero-centered data in hidden layers.
- Sigmoid: Best for binary classification in output layers.
- Softmax: Essential for multi-class tasks in output layers.
For more detailed insights, check out this guide on choosing the right activation function. Experimentation and benchmarking are key to finding the best fit for your specific needs.
Advanced Activation Functions and Their Applications
Modern advancements in activation functions have revolutionized how models process complex data. These innovations address limitations of traditional methods, offering improved performance and efficiency. From Leaky ReLU to GELU, these functions are reshaping the landscape of deep learning.

Leaky ReLU and Parametric ReLU
Leaky ReLU addresses the “dead neuron” issue by allowing a small gradient for negative inputs. This ensures all neurons remain active, improving model performance. The α parameter can be optimized for specific tasks, making it versatile for various architectures.
Parametric ReLU takes this a step further by learning the α parameter during training. This adaptability enhances its effectiveness in deep networks, particularly for image and text data. Both variants are widely used in modern applications due to their computational efficiency.
Exponential Linear Unit (ELU)
The ELU function introduces a log curve for negative inputs, improving gradient flow. This feature makes it particularly effective for self-normalizing networks, where stability is crucial. Its ability to handle negative values reduces the risk of dead neurons, ensuring consistent learning.
ELU’s smooth transition for negative inputs also enhances convergence speed. This makes it a strong choice for tasks requiring high accuracy and stability, such as natural language processing.
Swish and GELU Activation Functions
Swish, developed by Google Brain, has shown superior performance on benchmarks like ImageNet. Its smooth, non-monotonic curve allows for better gradient flow, making it a popular alternative to ReLU. Swish’s ability to handle complex data has driven its adoption in cutting-edge models.
GELU, used in models like BERT and RoBERTa, introduces a probabilistic formulation. This approach enhances its effectiveness in transformer architectures, particularly for tasks like language understanding. GELU’s unique design ensures robust performance across diverse applications.
“Advanced activation functions are pushing the boundaries of what models can achieve, enabling breakthroughs in AI research.”
| Function | Key Feature | Applications |
|---|---|---|
| Leaky ReLU | Prevents dead neurons | Image recognition, NLP |
| Parametric ReLU | Learns α parameter | Deep networks, text analysis |
| ELU | Log curve for negatives | Self-normalizing networks |
| Swish | Smooth, non-monotonic | ImageNet benchmarks |
| GELU | Probabilistic formulation | BERT, RoBERTa models |
From optimizing hardware acceleration to setting new SOTA benchmarks, these advanced functions are driving innovation in AI. Their adoption across industries underscores their importance in shaping the future of machine learning.
Common Challenges with Activation Functions
Implementing activation functions comes with its own set of hurdles that can impact model performance. From dead neurons to the choice between smooth and non-smooth functions, these issues require careful attention. Addressing them effectively ensures better learning and accuracy in your models.

Dead Neurons in ReLU
The ReLU activation function is widely used for its simplicity and efficiency. However, it suffers from the “dying ReLU” problem, where neurons become inactive and stop contributing to learning. Studies show this issue affects over 40% of neurons in some architectures.
To diagnose neuron saturation, monitor gradient flow during training. Tools like TensorBoard can visualize this process, helping identify inactive neurons. Proper weight initialization and techniques like batch normalization can mitigate this issue.
Adaptive activation methods, such as Leaky ReLU or Parametric ReLU, are effective alternatives. These functions ensure all neurons remain active, improving model performance and stability.
Choosing Between Smooth and Non-Smooth Functions
Smooth functions like sigmoid and tanh offer gradual transitions, making them ideal for certain tasks. However, they can suffer from vanishing gradients, slowing down learning. Non-smooth functions like ReLU avoid this but may introduce other challenges.
Here’s a quick comparison:
- Smooth Functions: Gradual transitions, prone to vanishing gradients.
- Non-Smooth Functions: Faster learning, risk of dead neurons.
Mixed activation architectures combine both types, leveraging their strengths. For example, using ReLU in hidden layers and softmax in output layers can optimize performance for complex tasks.
“Understanding these challenges is key to building robust and efficient models.”
Noise robustness is another consideration. Smooth functions handle noisy data better, while non-smooth functions are more efficient for clean datasets. Experimentation and benchmarking are essential to find the best fit for your specific needs.
Conclusion
The evolution of activation functions continues to shape the future of deep learning. From traditional sigmoid to advanced GELU, these tools have evolved to address challenges like vanishing gradients and dead neurons. Their role in enhancing model accuracy remains critical, even as automated discovery tools like AutoML streamline the selection process.
Emerging technologies, such as quantum computing, promise to redefine how neural networks process data. Sustainability considerations are also gaining traction, pushing for energy-efficient solutions. Cross-domain transfer learning further highlights the versatility of these functions, enabling applications across diverse fields.
When selecting an activation function, consider factors like task complexity, computational efficiency, and gradient flow. Experimentation and benchmarking are essential for optimal results. For further insights, explore community resources like TensorFlow and PyTorch documentation.
FAQ
What role do activation functions play in neural networks?
Activation functions introduce non-linearity, enabling the model to learn complex patterns. Without them, the network would only perform linear transformations, limiting its capabilities.
Why is non-linearity important in neural networks?
Non-linearity allows the model to capture intricate relationships in data. Linear models fail to handle complex tasks like image recognition or natural language processing effectively.
What are some common types of activation functions?
Popular choices include Sigmoid, Tanh, ReLU, and Softmax. Each has unique properties, making them suitable for specific tasks like classification or regression.
How does the ReLU function address the vanishing gradient problem?
ReLU avoids this issue by outputting zero for negative inputs and the input value itself for positive inputs. This simple mechanism ensures faster convergence during training.
What is the Softmax function used for?
Softmax is ideal for output layers in classification tasks. It converts raw scores into probabilities, ensuring the sum of all outputs equals one.
What challenges arise with the ReLU activation function?
ReLU can lead to “dead neurons” where certain neurons stop updating due to zero gradients for negative inputs. Variants like Leaky ReLU mitigate this issue.
How do activation functions impact model performance?
They influence convergence speed, gradient flow, and the ability to handle vanishing or exploding gradients. Choosing the right function is critical for optimal results.
What are advanced activation functions like ELU and GELU?
ELU and GELU are modern alternatives that improve performance in deep learning models. They address limitations of traditional functions like ReLU.
How do I choose the right activation function for hidden layers?
ReLU is commonly used for hidden layers due to its simplicity and effectiveness. However, alternatives like Leaky ReLU or ELU can be better for specific scenarios.
What is the difference between smooth and non-smooth activation functions?
Smooth functions like Sigmoid and Tanh have continuous derivatives, while non-smooth ones like ReLU are piecewise linear. The choice depends on the task and model architecture.
 By
By





